- AI Transformation
Our AI Team
Sofia
Ivan
Vlad
Anton
Technolody Stack
Our Clients
Featured Cases
- Services
Full Cycle Development
By Industry
- Works
Other projects
AI Learning PersonalizationSmart content recommendationsHotel AI ConciergeAI assistant for hotel guestsClaims Documentation AutomationPlatform for faster claims processingAI for Candidate ScreeningSmart HR efficiency boosterAI Voice AgentAI agent for hands-free learningLLM Legal SummarizationEfficient and fast legal summariesVision-Based Driving AssistanceReal-time threat detection system - Company
Yellow in Numbers
$2.1B+
Value generated through AI innovation47
Custom LLMs and AI agents deployed30M+
Engaging with products we created98%
Projects delivered within agreed budget











August 8, 2018
StickerBox–Episode 1: Why We Failed When We Tried to Segment Faces With Algorithms
With this article, we are launching a series of stories casting light on the ups and downs behind StickerBox. Spoiler: with all the downs, we made it!
The idea of StickerBox came to us when we found out that our corporate messenger Slack supports custom-made emojis. A nice way to cheer up boring corporate chats, isn’t it?
Indeed. Creating our own emojis for Slack became our favorite corporate pastime. Most of all, we enjoyed making emojis out of our teammates’ photos—the reaction was always priceless. Soon we figured: if we loved it so much, other people would also.
That’s how StickerBox, a mobile app allowing users to transform selfies or friends’ photos into stickers and share them across social media, was officially born. The idea was highly supported at a hackathon, so we decided to give it a go.
The main issue we had to resolve in order to let StickerBox see the light of day was face segmentation. We needed technology that would find a face and hair in a photo, separate them from the rest of the body, and cut them out from the background for further use. In this series of articles, we describe what we did to resolve the task step-by-step. Stay with us if you want to know the outcome!
Step 1: Defining object contours
What we used. We started with Canny Edge Detector, a mathematical algorithm that detects the edges of an object in an image. The idea was to use this algorithm so that StickerBox could define the contours of the face and hair in an uploaded image and further use them to create a sticker.
Did it work?

Original picture

Picture with detected edges after Canny Edge was applied
Not as we expected. As you can see in the picture above, the algorithm helped us reduce the amount of data to be processed by StickerBox as it removed colors and noise from the images. However, it couldn’t cut the face and hair out from the background and remove other objects from an image.
We solved this issue and we'll solve any other. Just contact us, and we'll show you what we are capable of
we love tricky cases!Step 2: Recognizing the face boundaries
What we used. Now that we could detect the contours of the face and hair, we needed to remove the background and the rest of the objects from an image. To do that, we used an algorithm that detects facial landmarks: the nose, mouth, and eyes. Taking them as starting points, the algorithm defined the potential contours of a face and drew a "donut" (as we call it) around them, while the other objects remained unidentified and were automatically removed from the image.
Did it work?

Finding the face landmarks (nose, eyes, mouth, ears)

Creating the "donut", which predicts the area that should contain the face boundaries
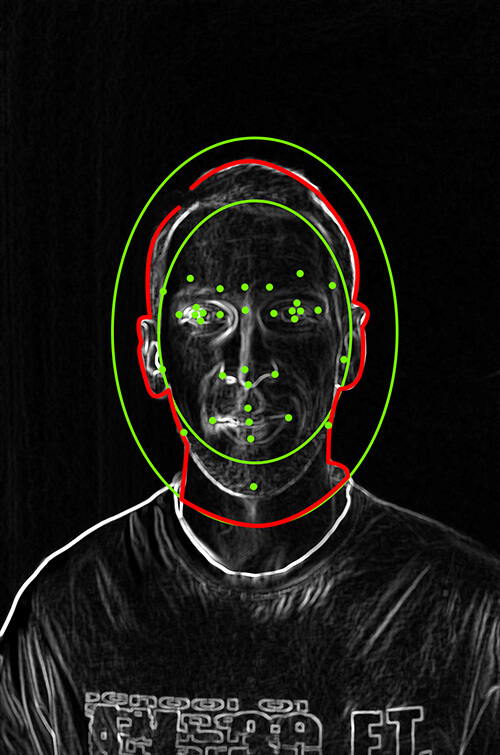
Telling the face edges apart from the other edges (by finding the intersection between edges found by the Canny Edge Detector and the head area predicted by the "donut")

Applying the mask to the original image
The red line in the above picture displays the actual result the algorithm produced in most cases—a face with distinct contours and no redundant objects in the background.
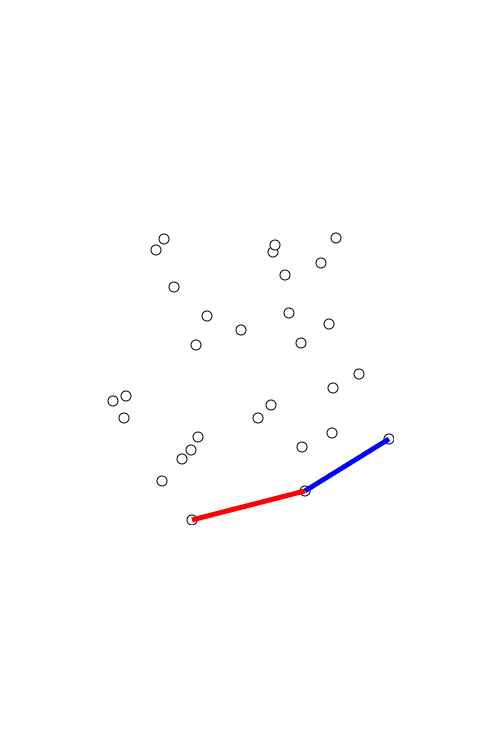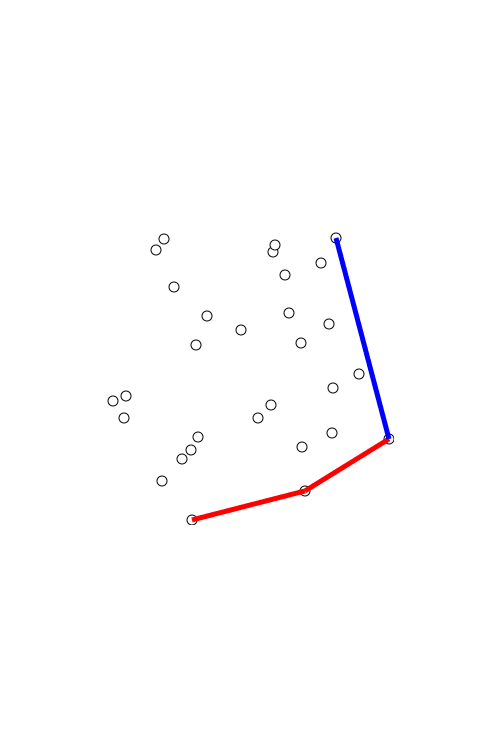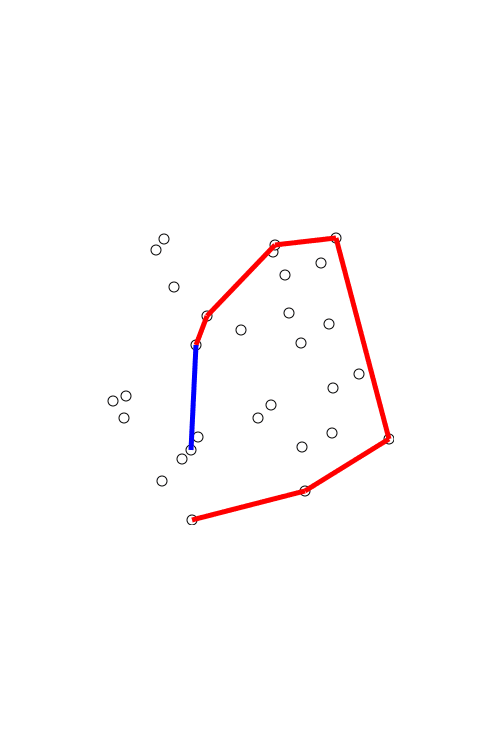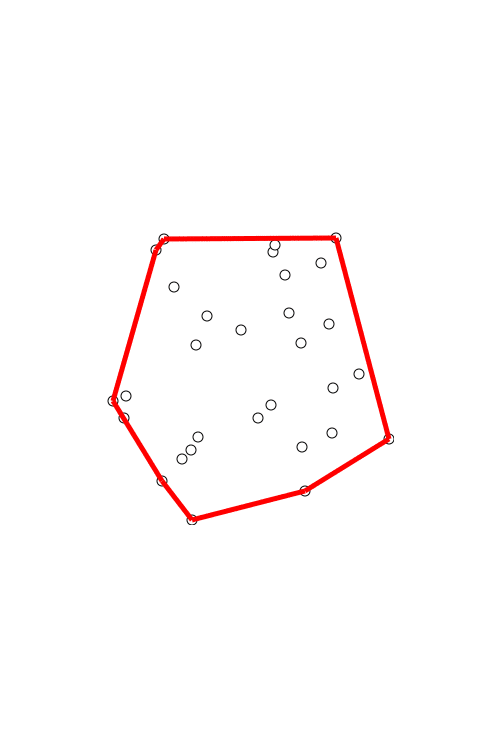
However, another problem emerged. Occasionally, the algorithm might leave contours not connected at random spots (see the picture below). As a result, when we applied filling to the face, it was applied to the unnecessary parts in the image as well.

Unconnected contour
Step 3: Connecting contour ends. Method A
What we used. First, we tried the superpixels method. The algorithm worked simply: it detected the places where the face contours were not connected and enlarged the radius of pixels there to connect the contour ends together.
Did it work?

Not in 100 percent of the cases, as seen above. If the gaps between the contour ends were too big, the pixels also became too large and the final picture looked a bit crooked
Step 3: Still connecting the contour ends. Method B
What we used. The Graham algorithm was another option we resorted to when trying to connect face contours. The algorithm took the existing face contours as a baseline and wrapped them around with another line, thus removing gaps between unconnected pixels.
Did it work?
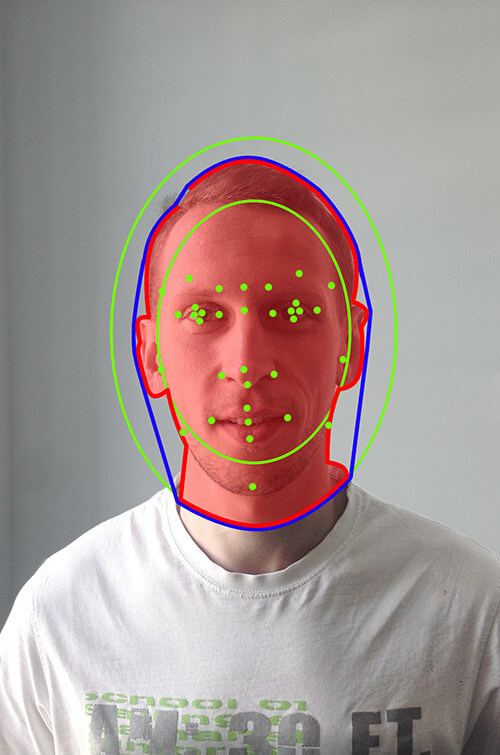
In most cases, yes, when it did not occasionally include irrelevant pixels to an image, as you can see in the picture above (outlined with the blue line)
A pivot in the approach: Trying to detect face color
What we used. At this stage, we decided to change the method. We used Color Blob Detection, an algorithm detecting the color of objects rather than their contours. The algorithm took a sample of face and hair color and then applied it to the entire area.
Did it work?

Finding the face landmarks

Outlining the predicted face area and recognizing face color pallette

Applying the Color Blob Detection method with the palette that we extracted
Not always. Sometimes, there were problems with defining hair color, especially when the hair was too short or dyed several colors. The same problem occurred with beards. Moreover, the face filling was sometimes also automatically applied to necks, obviously because they are the same color as faces, as you can judge from the picture above.

Sometimes, the hair was not included because of the color difference
Conclusion
The result that was provided with the help of algorithms described above was not bad, but not good enough and quite unstable. Well, at least, we learned a lesson. Not everything in software can be done algorithmically; sometimes we need something “cleverer.”
In the next article, we are going to tell you how neural networks helped StickerBox see the light of day. Stay tuned!
We love what we do, contact us and let's skyrocket your product together!
Get in touchGot a project in mind?
Fill in this form or send us an e-mail
Subscribe to new posts.
Get weekly updates on the newest design stories, case studies and tips right in your mailbox.