










Customer Feedback Insights Engine
Analyzing feedback in the fastest and most efficient way
AI development
Productivity
6 weeks
Web
About the project
Our client was a US-based B2B SaaS company. The client’s product and CX teams struggled to keep up with user feedback across multiple channels, including G2 reviews and in-app feedback. They were missing clear signals in the noise, so they partnered with us to build an LLM-based solution for gathering feedback insights.
The client had
Existing product
Established product stack
We were responsible for
Designing system architecture to process feedback from multiple sources
Selecting and fine-tuning LLM for domain-specific sentiment analysis
The development of clustering and summarization pipelines
Setting up CI/CD pipeline, monitoring, and model performance tracking
Project Team
Project manager
Software architect (part-time)
ML engineer
Backend engineer
Frontend engineer
DevOps engineer (part-time)
QA engineer (part-time)
Key features delivered
The final solution consists of several key features.
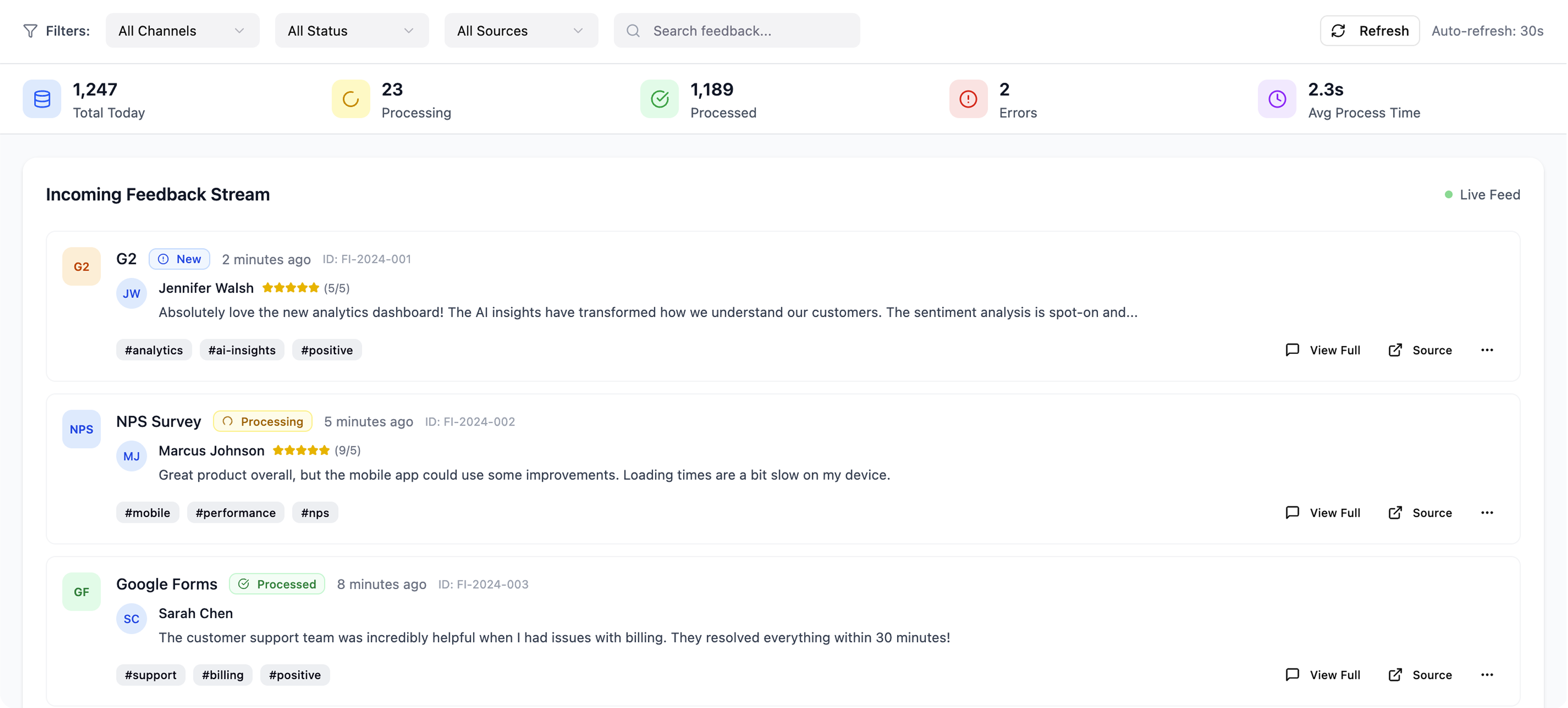
Feedback ingestion layer
Unifies feedback ingestion from 4+ sources like G2 reviews, in-app feedback forms, Google Forms, Typeform, and NPS responses.

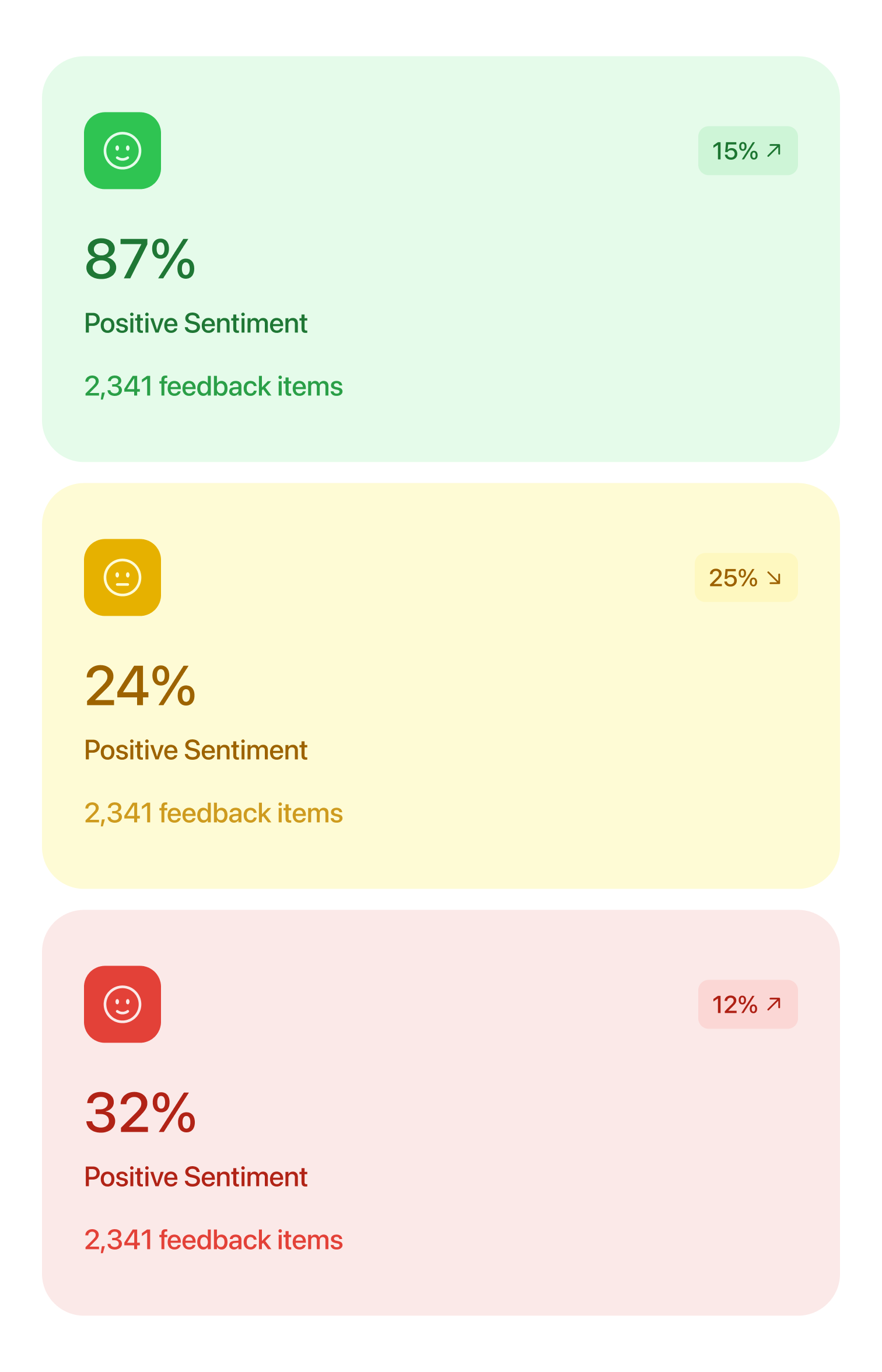
AI sentiment analysis engine
Processes each piece of feedback with the help of an LLM and sentiment model to classify and tag tone and emotional intensity.

Feature request clustering
Groups similar feedback based on topic and intent to help the team identify common pain points or requests.
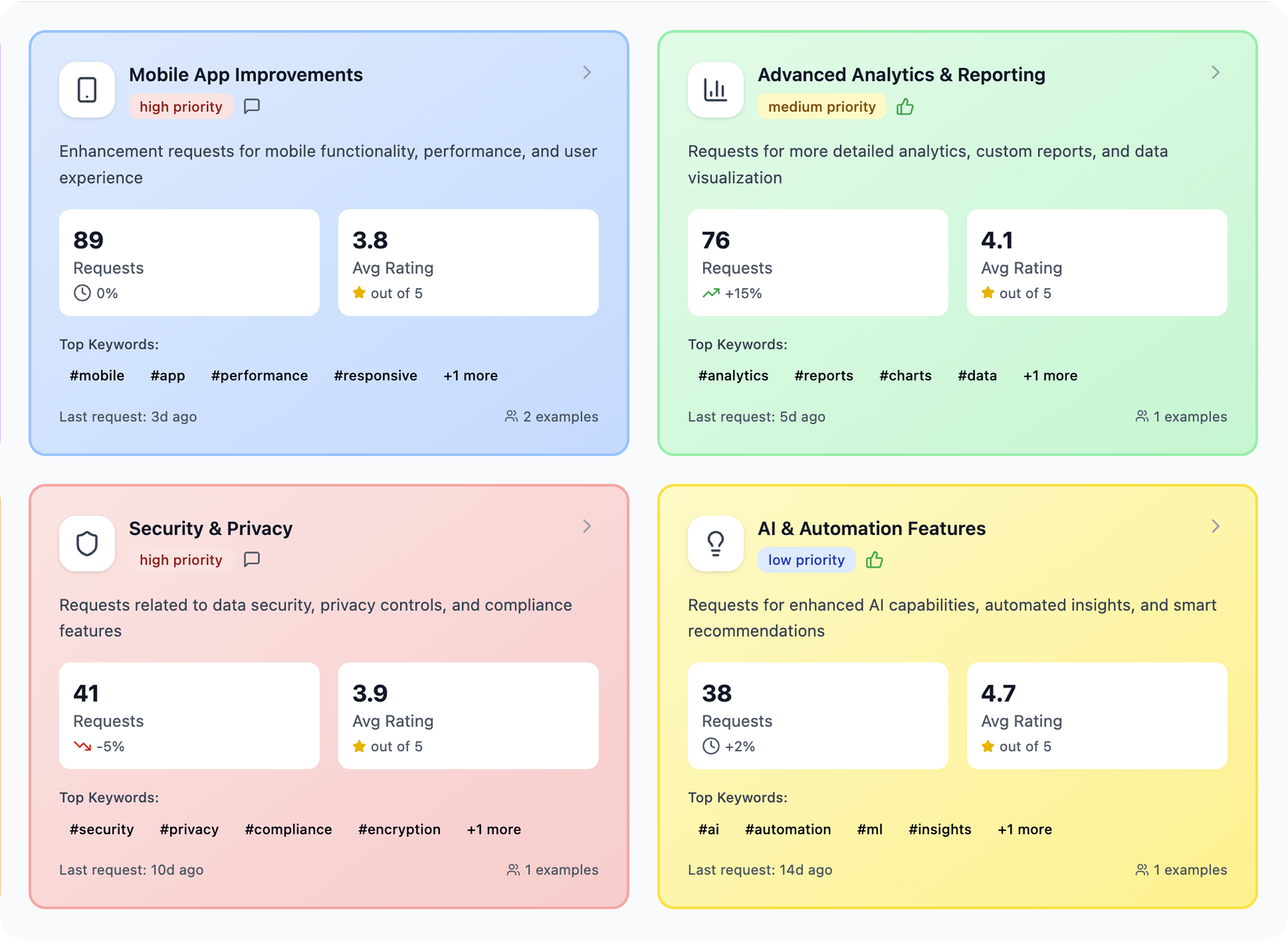

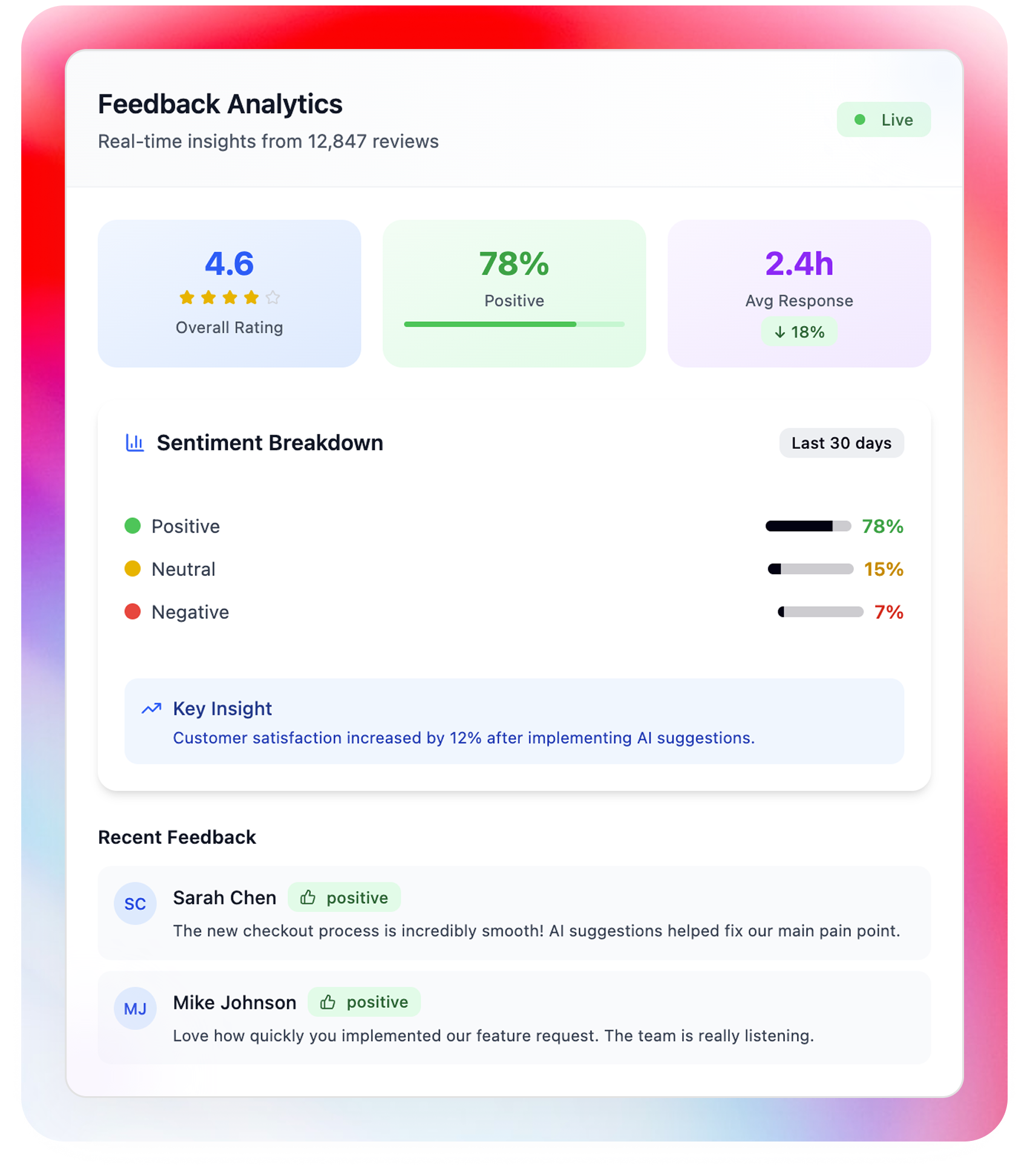
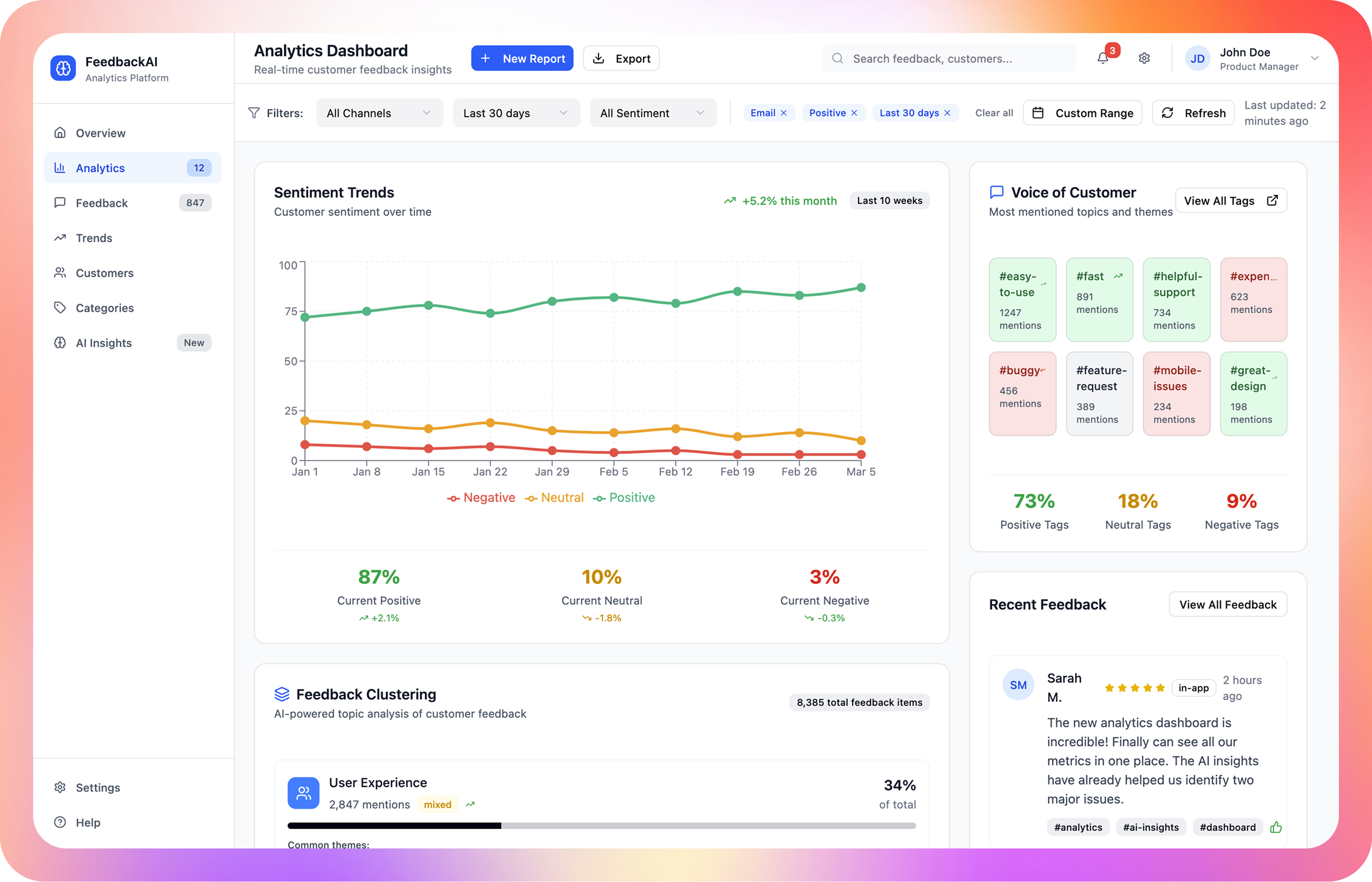
Insights dashboard
Internal tool for analyzing feedback tone and following user satisfaction metrics over time, with sentiment timeline and "Voice of Customer" summary cards.
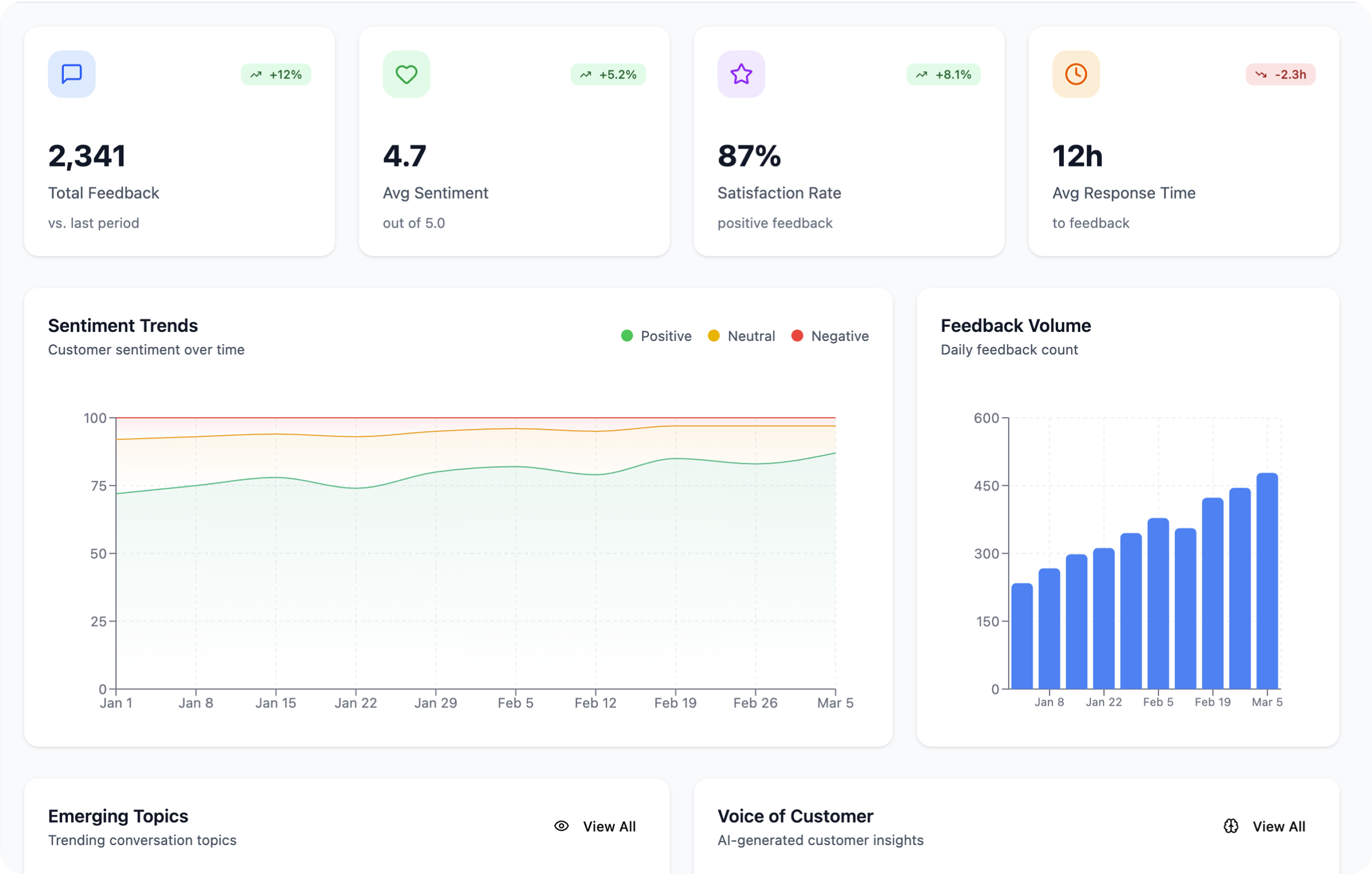

More features
Weekly Slack digest
Monthly product insights report
Jira integration to create draft tickets from high-frequency requests
Feedback trend analysis over time
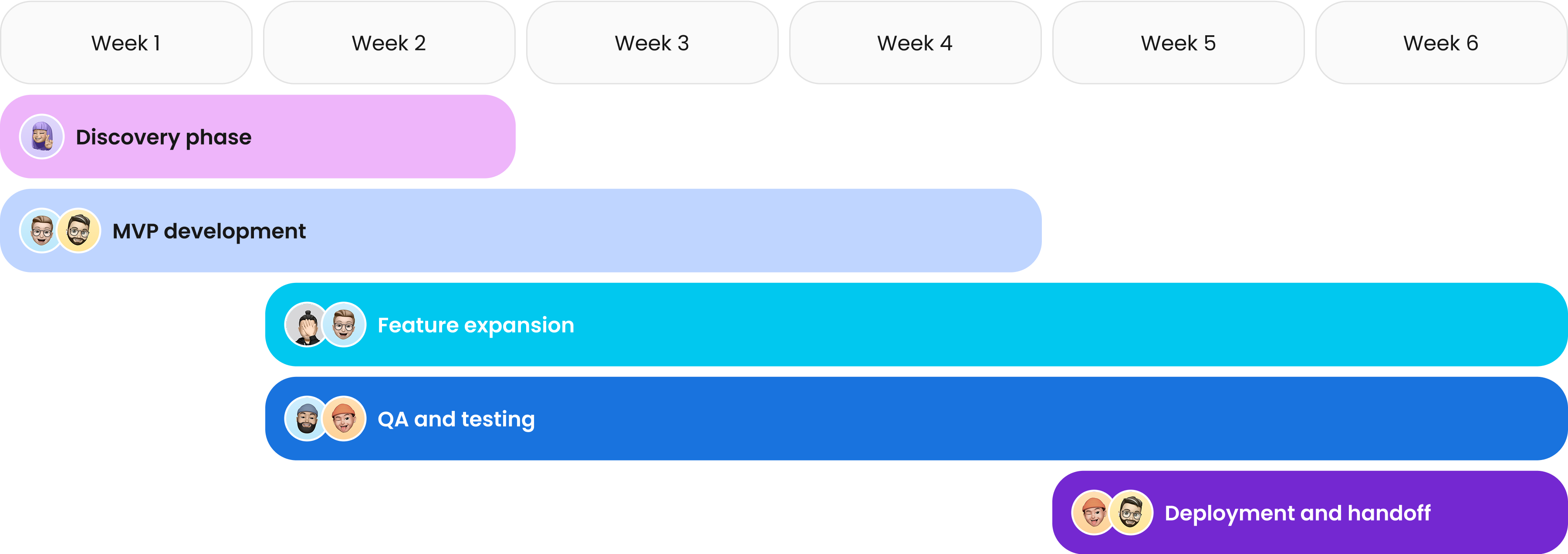
Project timeline
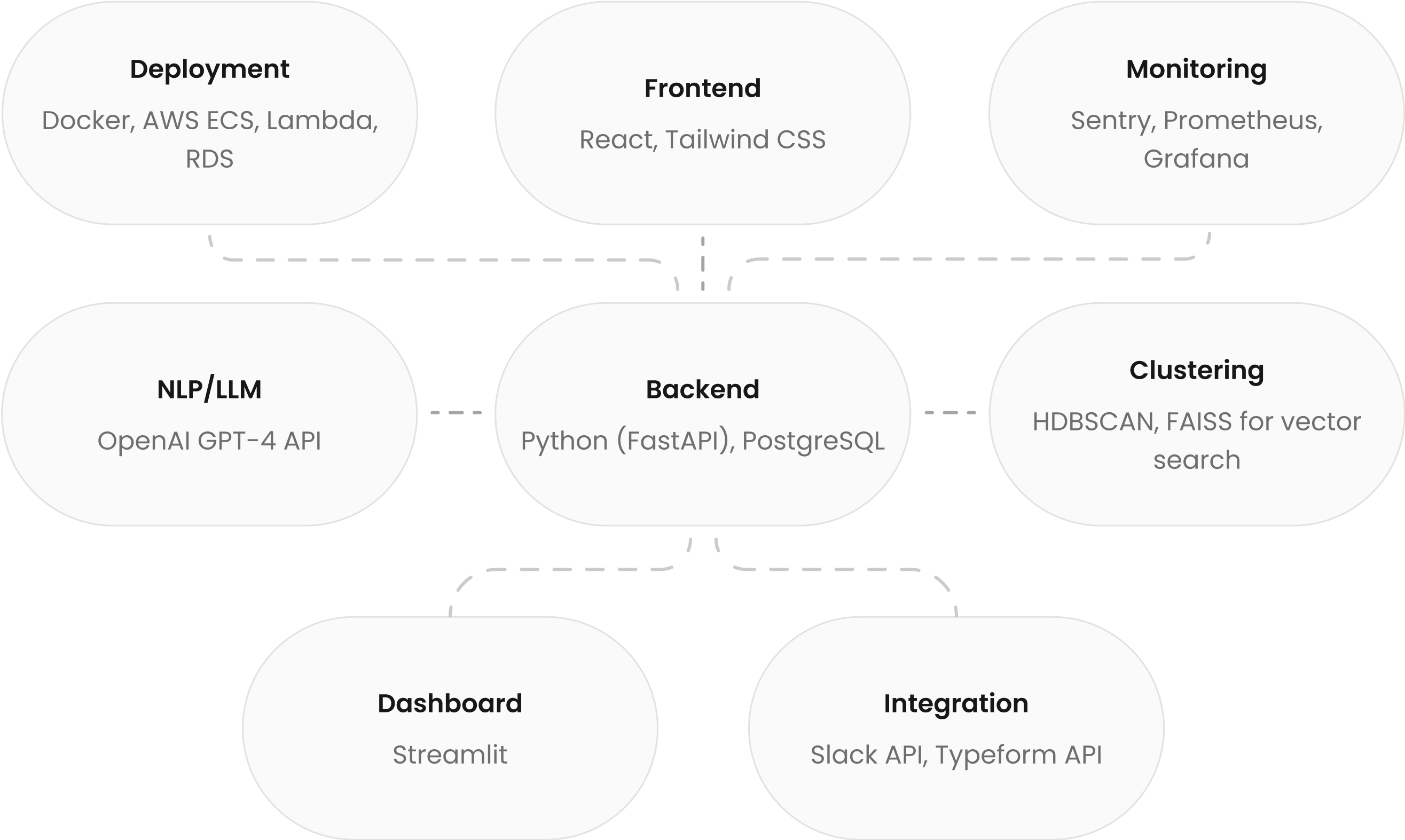
Tech stack
The technologies we used to realise the LLM integration smoothly.
Project challenges and solutions
What challenges our team faced and how we overcame them.
Feedback duplication across channels
Problem: Users sometimes say the same thing across different channels. Duplicates inflated cluster weights and caused noise in insights.
Solution: We embedded each feedback entry as a vector and used semantic deduplication (cosine similarity + timestamp thresholds) and applied near-duplicate suppression logic in clustering to avoid double-counting.
Dynamic feedback topics
Problem: New issues and requests emerge over time (for example, when a new feature suddenly gets lots of complaints), making static topic taxonomies brittle.
Solution: Our team used unsupervised clustering (HDBSCAN + embeddings) so new topics would emerge naturally. We also enabled human curation: Product managers could rename clusters and map them to the internal product taxonomy.
Overwhelming the client with data
Problem: In the first version, the system produced too much information. Stakeholders struggled to separate signal from noise.
Solution: We revised the app’s UX and prioritized simplicity by introducing clear charts, summaries, and filters.
Scaling to handle large volumes
Problem: Once historical feedback was imported (~40k records), clustering and semantic search became slow.
Solution: We switched to FAISS (Facebook AI Similarity Search) for scalable vector search and used AWS Lambda and S3 for parallel processing of incoming data.
Result
42% decrease in average time to identify actionable feedback
Product team adopted the dashboard as a key decision-making tool
Improved cross-team collaboration (Product, CX, Marketing)

