- AI Transformation
Our AI Team
Sofia
Ivan
Vlad
Anton
Technolody Stack
- Services
- Works
Other projects
AI Learning PersonalizationSmart content recommendationsHotel AI ConciergeAI assistant for hotel guestsClaims Documentation AutomationPlatform for faster claims processingAI for Candidate ScreeningSmart HR efficiency boosterAI Voice AgentAI agent for hands-free learningLLM Legal SummarizationEfficient and fast legal summariesVision-Based Driving AssistanceReal-time threat detection system - Company
Yellow in Numbers
$2.1B+
Value generated through AI innovation47
Custom LLMs and AI agents deployed30M+
Engaging with products we created98%
Projects delivered within agreed budget











September 6, 2021
How to Secure a REST Web Service: The Full Guide
From basic authentication to JSON web tokens—four ways to implement user authorization in a nutshell.
REST is a modern architectural style that defines a new approach to designing web services. Unlike its predecessors, HTTP and SOA, it’s not a protocol (read: a strict set of rules), but rather a number of recommendations and best practices of how web services should communicate to each other and how to secure REST services. The services that are developed in compliance with the best REST practices are called “RESTful web services.”
Security is a cornerstone of RESTful web services. One of the ways to enable it is a proper in-built user authentication and authorization mechanism.
There are lots of ways to implement user authentication and authorization within the RESTful web services. The main approaches (or standards) we are going to talk about today are the following:
- Basic authentication
- OAuth 2.0
- OAuth 2.0 + JWT
To make our discussion more specific, let’s assume that we have microservices on the backend of our application, and upon each user request, several services at the backend have to be called to collect the requested data. Thus, we will examine each standard not only in terms of security issues, but also in the context of additional traffic and server load they generate. Here we go.
What is a RESTful API and how does it work?
Let’s start with a definition of API itself. API is short for an Application Programming Interface. It means a set of operations that allow software parts to communicate with each other. An API provides developers with building blocks so they can build a proper solution. Depending on the specifications, APIs may vary and developers can use only parts that they need.
Now we define RESTful. REpresentational State Transfer (or REST) is an architectural style that guides developers on the way to creating a web service. There are six main constraints that REST applies:
- Uniform Interface
- Stateless
- Layered System
- Client-Server
- Cacheable
- Code on Demand
Thus, a RESTful API is a programming interface that follows the REST principles and provides communication between RESTful web services.
Common API Security Challenges
Since nothing is perfect in this world, security implementation in RESTful web services has some points to consider before starting working on them.
DOS attacks
A Denial of Service (or DOS) attack implies that an attacker sends an overwhelming number of messages with requests that have an invalid return address. RESTful API can easily shut down because of it.
Despite the fact that your API may not be revealed to the public, it still can suffer from DOS attacks. Since such an attack can damage the access to the API for everyone—your clients, partners, apps, devices, and more), you should pay a lot of attention to security.
Farming
There are plenty of websites that use information from other sources to show the client the best buying deals, for example. To do that, they may take advantage of other services’ APIs to accumulate information. That is what farming looks like.
When you implement authentication, it prevents your API from exploitation and overloading.
Man-In-The-Middle
When this type of attack happens, a hacker is located right between a sender and a recipient. It can be a transparent attack or the hacker can pretend to be one of the parties. The final goal is to get access to unencrypted information.
Transport Layer Security (TLS) and Secure Sockets Layer (SSL) protocols can save the day here. The right configuration of TLS/SSL can provide secure and clear communication between a client and a server.
Now, let’s talk about the standards of REST security in more detail.
Basic authentication
The oldest and the simplest standard on the list.
What it looks like: username + password + Base64 (a basic algorithm of hashing usernames and passwords).
How it works: Imagine that a user tries to log into their Facebook account to access feed, instant messages, friends, and groups, which are all separate services. After the user inserts their username and password, the system knows they are allowed to enter and lets them in. However, it doesn’t know by default what are their roles and privileges, what services they are allowed to access, etc.
So every time the user tries to access any service, the system should once again verify if they are allowed to do this, which implies an additional call to the authentication server. As far as there are four services in our example, there will be four additional calls per user in this case.
Now imagine that we have 3K user requests per second, though in case of Facebook 300K sounds more realistic. Multiplying them by four services, we will end up with 12K calls to the authentication server per second.
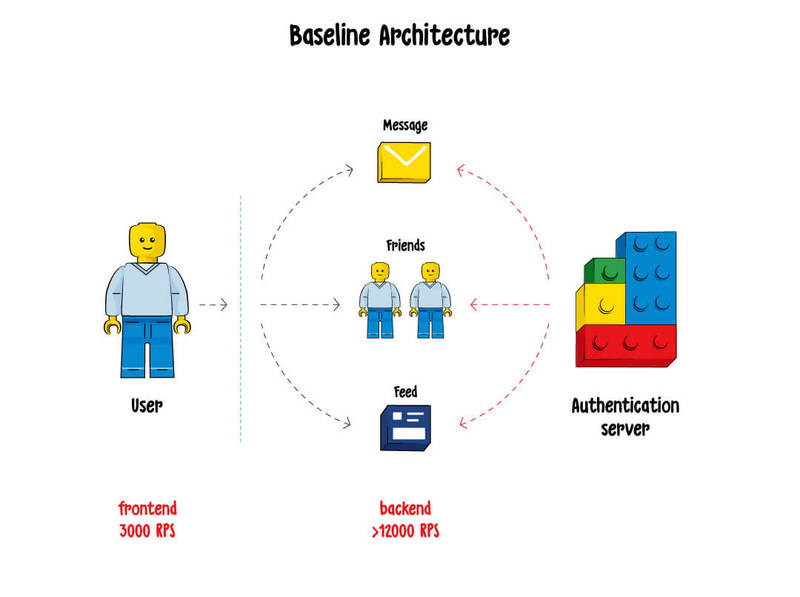
Summary: bad scalability, a huge amount of additional traffic that does not bring business value, significant load on the server.
OAuth 2.0
What it looks like: username + password + access token + expiration token
How it works: The main idea of the OAuth 2.0 standard is that after a user logs into the system with their username and password, a client (a device the person uses to access the system) receives a pair of tokens, which are an access token and a refresh token.
The access token is used to access all services in the system. After it expires, the system uses the refresh token to generate a new pair of tokens. So, if a user enters the system every day, the tokens will also be updated every day, and there will be no need to log into the system with username and password every time. The refresh token also has its expiration period (though it's much longer than the one of the access token), and if a user hasn't entered the system for—let's say—a year, they are likely to be asked to insert the username and password again.
The OAuth 2.0 standard came to replace the basic authentication approach, and it has certain advantages, such as that a user doesn't have to insert username and password every time they want to enter the system. However, the system still needs to make calls to the auth server, as in the case with the basic auth approach, to check what what the user who owns the token is authorized to do.
Let's imagine that the expiration date is one day. That implies significantly less load on the login server, because a user has to insert their credentials only once a day, not every time they want to enter the system. However, the system still needs to verify each token and to check out the user roles as well as store state somewhere. So, we again end up with multiple calls to the authentication server.
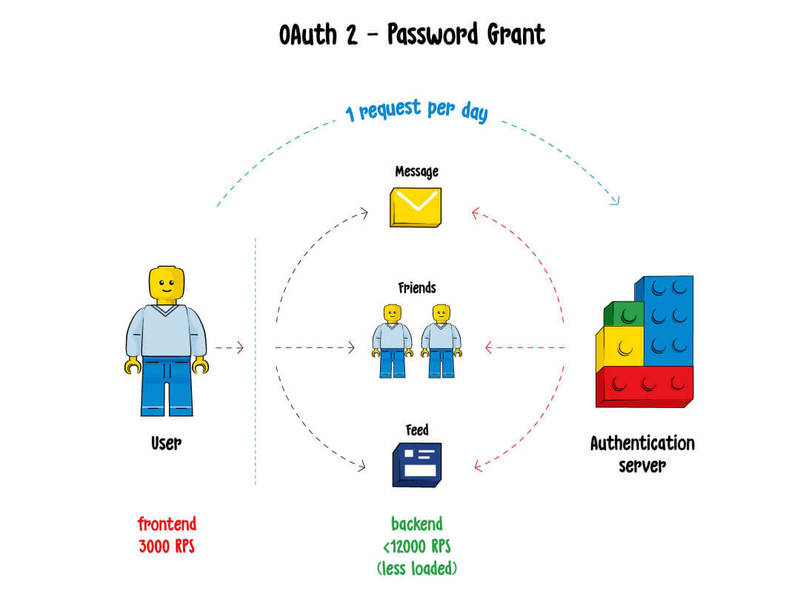
Summary: same issues as with the basic authentication approach—bad scalability and a huge load on the authentication server.
OAuth 2 + JSON Web Tokens
What it looks like: username + password + JSON map + Base64 + private key + expiration date
How it works: When a user logs into the system with their username and password for the first time, the system returns back not just an access token, which is simply a string, but a JSON map containing all user information, such as roles and privileges, encoded with Base64 and signed with a private key. This is how it looks with and without encoding:

Looks scary, but this actually works! The main difference is that we can store state in the token, while services stay stateless. This means that the users themselves hold their own info and there is no need for additional calls to retrieve it as everything is already inside the token. And this is a huge deal in reducing the load on the server. This standard is widely used all over the world.
Summary: good scalability, works fine with microservices.
How to apply security on RESTful web services
We listed possible ways to secure your REST web service. Here are some more tips that will help you enhance the security level even more:
- HTTPS protocols will keep all your communication safe.
- The higher the level of encryption for all elements, the better.
- Sending any credentials and keys as query parameters is dangerous since they will be displayed as a part of the URL.
- Always validate the input data. Always.
Bonus: Amazon approach
..and a free consultation! Just contact us:)
Get in touchA brand new, fancy approach, called HTTP signatures. Amazon is one of the big players currently using it.
The main point is that when you create an Amazon account, they generate a permanent and super secret access token, which you should store very carefully and never show to anyone. When you need to request some info from Amazon, you take all http headers, sign them with this private token, and send this string as an additional header.
On the server side, Amazon also has your super private access key. What they do next? They simply take your http headers and sign them with this key. Then, they just compare this string with what you’ve sent as a signature string; if they are identical, then you are really who you said you are.
The great benefit is that you have to send your username and password only once—to receive the token. As for the headers signed with the private key, there is literally no chance to encode them. Even if someone intercepts the message—who cares ;)
Summary
Security is an urgent matter for a modern technological world. The more security methods people create to protect valuable information, the more ways other people find to get access to it. If you follow any of the mentioned standards for the RESTful web service, you can be sure that everything will stay protected.

Got a project in mind?
Fill in this form or send us an e-mail
🔐 What is a RESTful API?
🔐 What challenges should I expect with the RESTful API?
🔐 How can I secure my web REST web servicer?
🔐 Why is Amazon different?
Subscribe to new posts.
Get weekly updates on the newest design stories, case studies and tips right in your mailbox.