- AI Transformation
Our AI Team
Sofia
Ivan
Vlad
Anton
Technolody Stack
- Services
- Works
Other projects
AI Learning PersonalizationSmart content recommendationsHotel AI ConciergeAI assistant for hotel guestsClaims Documentation AutomationPlatform for faster claims processingAI for Candidate ScreeningSmart HR efficiency boosterAI Voice AgentAI agent for hands-free learningLLM Legal SummarizationEfficient and fast legal summariesVision-Based Driving AssistanceReal-time threat detection system - Company
Yellow in Numbers
$2.1B+
Value generated through AI innovation47
Custom LLMs and AI agents deployed30M+
Engaging with products we created98%
Projects delivered within agreed budget











May 21, 2019
How to Make a Scalable Web Application: Architecture, Technologies, Cost
Any application can be made scalable if designed properly. Agree? In our new article, we identify the most common scalability bottlenecks in the app architecture and explain how to avoid them at the engineering stage. Enjoy!
It always happens like that: when just a couple of users (read: a QA engineer and a customer) are using the software simultaneously, it works fine. However, after release, everything may suddenly become worse as the app is getting popular and attracting users all around the globe.
As the number of requests multiplies, it becomes clear that the server is simply not ready to accommodate a growing audience. When the load reaches the point where every new portion of requests is similar to a DDOS attack, the server eventually burns out and the app crashes.
To avoid this, web application scalability should be in the DNA of your project.
This metric is not primarily a matter of how capable your server is. Even the most powerful server still has limited RAM and CPU capacity. It’s rather a matter of the app architecture. Every web solution can smoothly grow if properly architectured.
In the article, we’re going to identify web scalability definition, principles of scalable web architecture, and avoiding bottlenecks in development.
The definition of web scalability
The easiest definition of scalability would sound like the ability of a web app to deal with increasing load without breaking down. It means that no matter how many users on how many platforms are present in one moment, the app will perform equally well for all of them.
The importance of scalability is clearly seen from the number of concurrent users on the most popular websites. The estimation study shows that the amount of people present on YouTube, Facebook, or Amazon at the same time is immense.
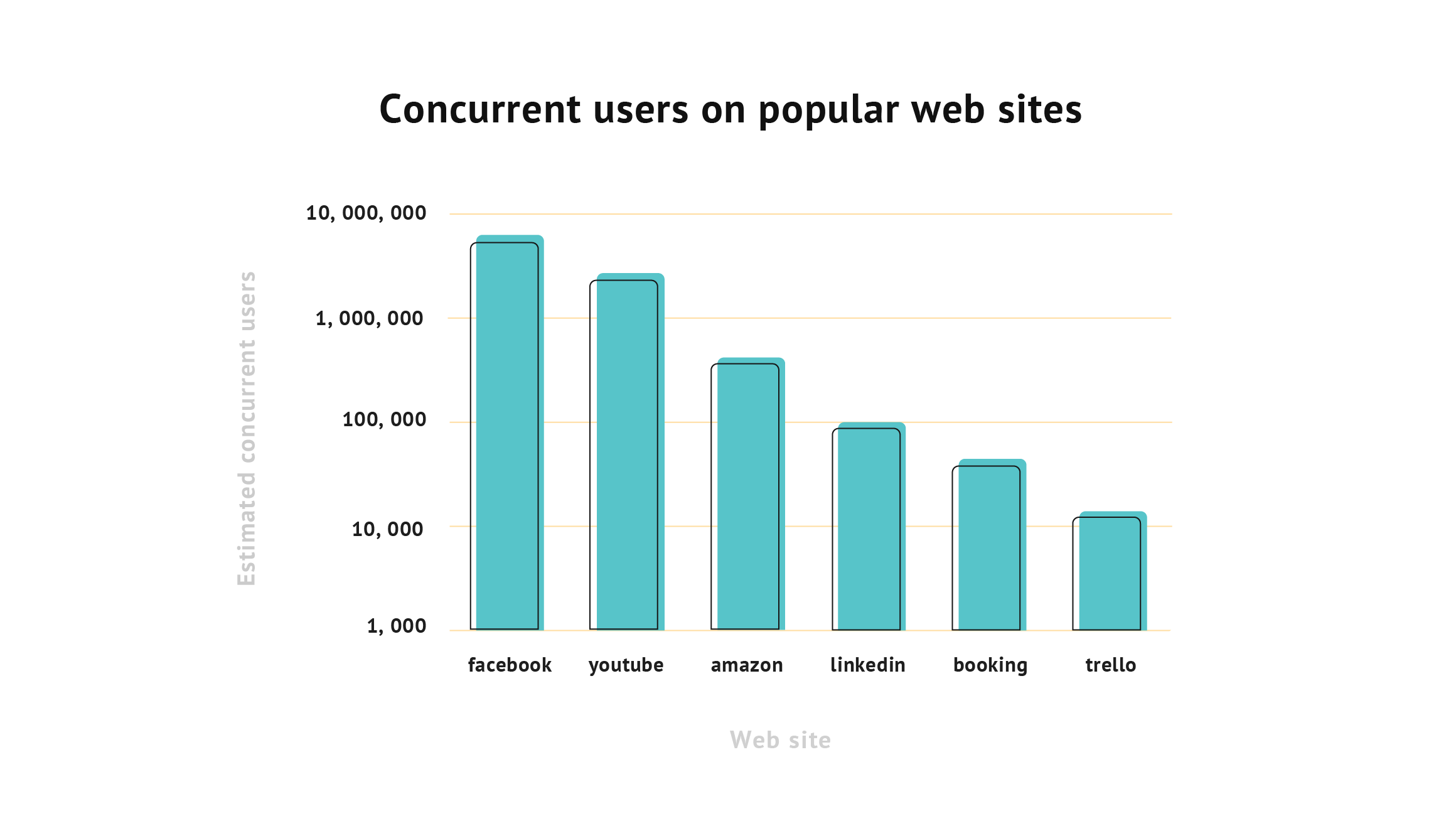
The app can become largely scalable with the ratio of the increase in performance to the rise in resources used. Also, it becomes easy to add more resources while keeping the whole structure untouched. If the system’s scalability is poorly built, adding more resources to it will not make a lot of difference to the app’s performance.
A saturation point is a workload intensity at which the app starts failing. Usually, it’s not about a gradual load raise, but about sharp unexpected increases. The ramp-up testing is aimed to identify this point and define the bottlenecks that undermine the system’s work.
Well-known examples of scalable web applications
Here are the most well-known web apps that made scalability one of their core elements.
- Bitly
Bitly is the app that provides link optimization services to individuals and businesses. Bitly helps improve interactions with customers and build brand awareness. Also, the app has data collection and real-time analytics functionality, so it becomes easy to monitor business performance.
- Slack
Slack is a business app that helps to connect employees. It has rich functionality that simplifies teamwork:
- Channels for different topics
- Searchable history to find the necessary data
- Video calls and screen sharing for more high-quality communication
Slack is available on any device, so it’s easy to find and access the team whether a user is at their desk or on the go.
- Dropbox
Dropbox is one of the most famous file-sharing services. The solution makes it possible to keep business data securely and enhances teams’ collaboration by bringing it to one place. Dropbox is used by Spotify, National Geographic, and other businesses, both big and small.
Why should you build a scalable web application?
When developing a web application, you may wonder why there is so much buzz around web scalability. Why should you focus on it?
Imagine that your marketing campaign for a trip planner app attracted lots of users and, at some point, the app has to simultaneously serve hundreds of thousands of them. That means millions of requests and operations processed at the same time and a high load on your server. If designed improperly, the system just won’t be able to handle it.
And what happens next? Random errors, partial and slow-loading content, endless waiting, Internet disconnection, service unavailability – nothing good will come of it. Most of your users will be lost, the product rating will become lower, and the market will be full of negative reviews.
Other problems that an unscalable web app can face are:
- Expansion of the product range raises the load time
- Updating becomes problematic
- Hanging the code structure becomes complicated
- Adding new pages takes too much time
That’s why the issue of designing scalable web applications must be of the highest priority. By paying more attention to this aspect, it’s easier to:
- Reduce the page load time and the number of errors
- Improve the user experience
- Lessen time and money spent on updating
- Increase brand loyalty
One of the greatest ways to make your web app scalable is to implement microservices. This architecture helps speed up the launch process and avoid a lot of scalability issues. Also, microservices make teams more independent and boost app resilience.
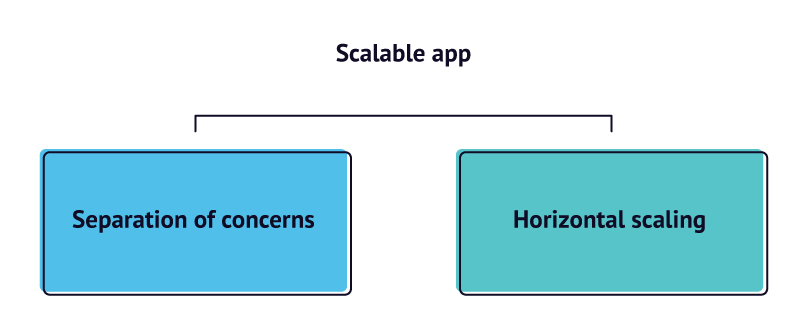
Introduction to the scalable app architecture
There are two main principles underlying the architecture of any scalable software platform: separation of concerns and horizontal scaling.
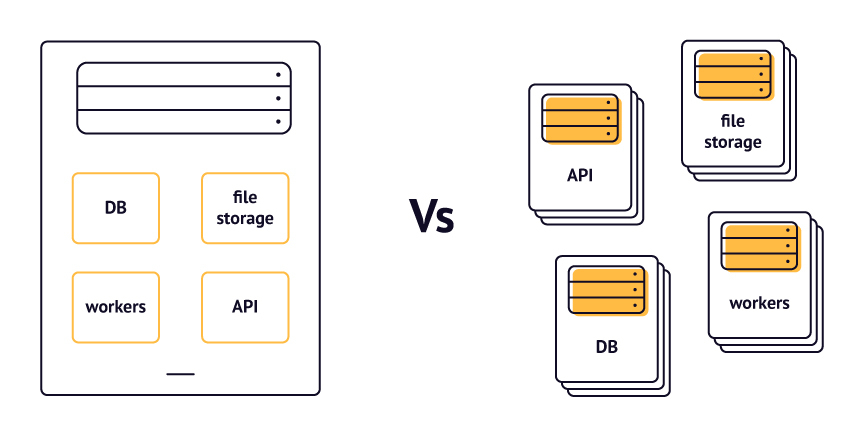
Separation of concerns
The idea behind the separation of concerns is the following: there should be a separate server for each type of task. What does that mean?
Sometimes apps are engineered in a way that one server does the whole job: handles user requests, stores user files, etc. In other words, it does the job that should normally be done by several separate servers. Consequently, when the server gets overloaded, the entire app is affected: pages won’t open, images won’t load, etc. To avoid this, ensure the separation of concerns.
For example, an API server handles priority client-server requests that require an instant reply. Let’s say, a user wants to change their profile image. After the image is uploaded, it usually undergoes certain processing: for example, it can get resized, analyzed for explicit content, or saved in storage.
Apparently, processing is a complex task that takes time. However, the user doesn’t have to wait until it's over — they can continue using the app while their new profile image is getting processed. Therefore, technically, the task is a low priority because it doesn’t require a real-time reply from the server. That’s why it would be reasonable to allocate it not to the API server, but rather to one specifically designated for this kind of job. For example, GPU servers are a good choice when you need to analyze images for explicit content.
Separation of concerns is vital for a scalable web application architecture not only because it enables distributing different types of tasks between dedicated servers, but also because it's a foundation for horizontal scaling.
Horizontal scaling
How many requests is your server able to handle? Basically, it depends on its specifications: RAM and CPU capacity. What happens when there is only one server that handles all of the tasks? After the load goes beyond the server capacity, the server crashes and the app doesn’t respond until the server recovers.
The idea behind horizontal scaling lies in the distribution of the load between several servers. Each server runs a snapshot (or a copy) of the application and is enabled or disabled depending on the current load. Distribution of the load is carried out by a special component — Load Balancer.
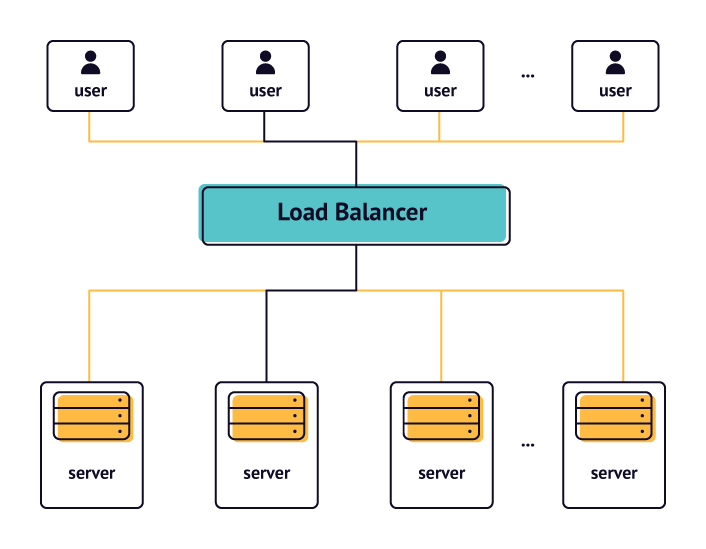
The Load Balancer controls the number of servers required for the smooth operation of the app. It knows how many servers are working at the moment as well as how many are in idle mode. When it sees that a server works at the top capacity and the number of requests is growing, it activates other servers to redistribute the load between them. And vice versa: it disables unneeded servers when the number of requests is reducing. Moreover, when one server goes out of order, the Load Balancer detects it by using Health Checkers and redistributes the load between the “healthy” servers.
The Load Balancer uses various algorithms for load distribution: Round Robin, Random, Least Latency, Least Traffic, etc. These algorithms can take into account such factors as geographical proximity (a user request is directed to the closest server), each server’s working capacity, etc.
Horizontal scaling doesn’t require you to scale the entire app or website when there’s a problem with one server. For example, when the API servers are reaching the breaking point, the load balancer activates more API servers without affecting the others. That’s one of the reasons why the separation of concerns is so crucial for horizontal scaling.
Now let’s see how the separation of concerns and horizontal scaling work together.
Building scalable web applications and websites
So, how to avoid scalability bottlenecks and build scalable web applications or websites? Let’s take a look at a well-designed scalable software.
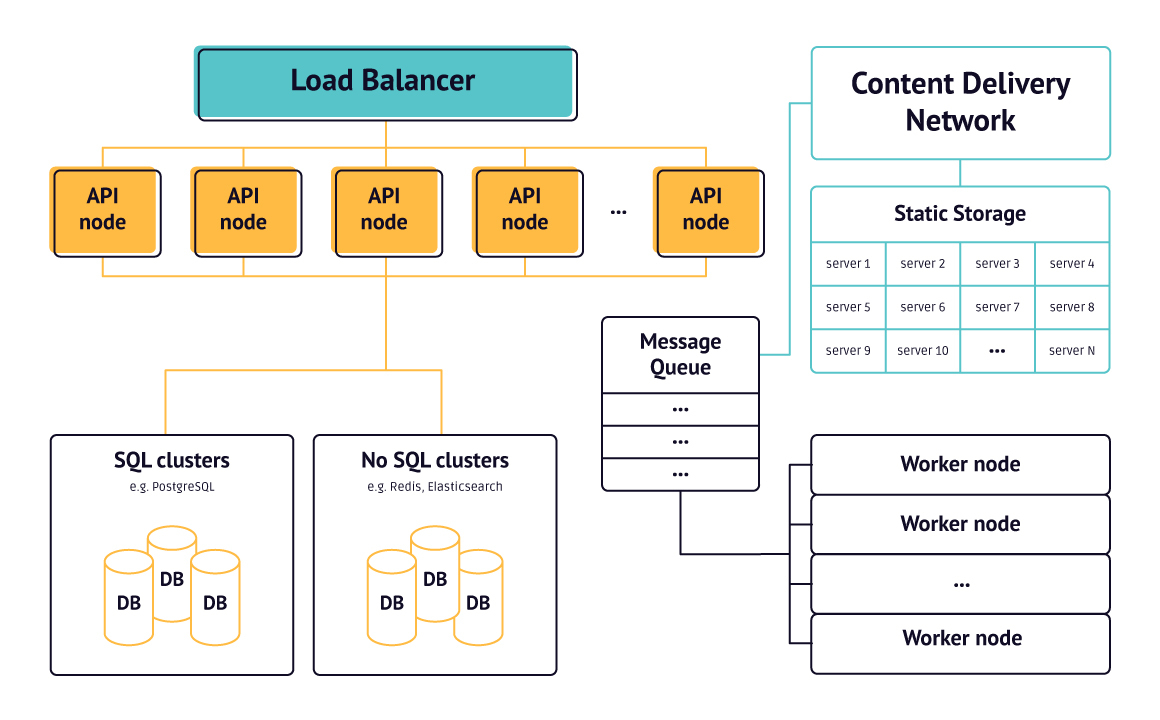
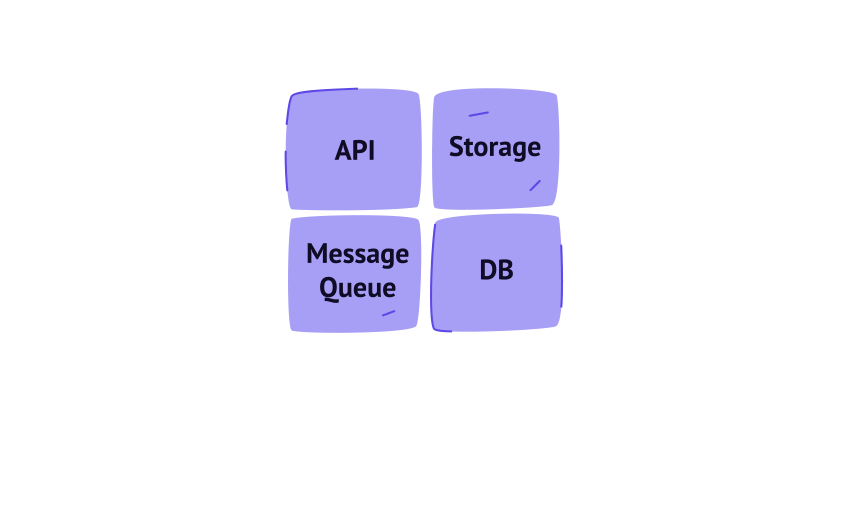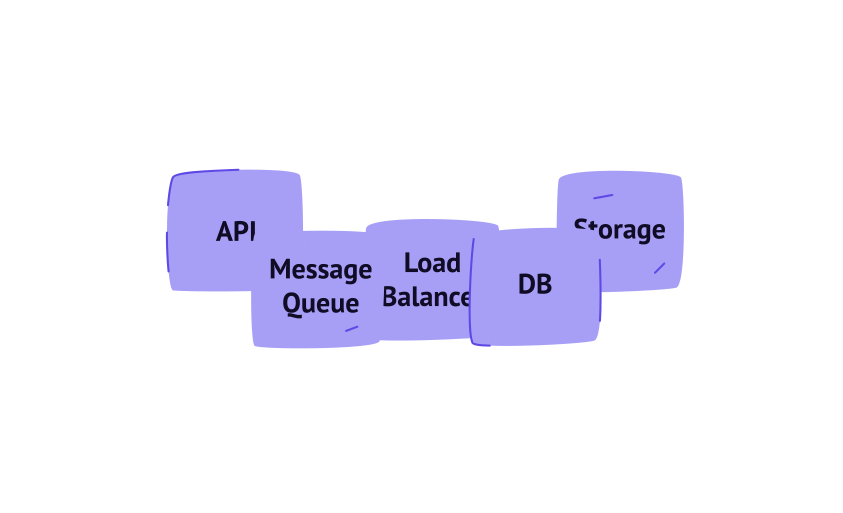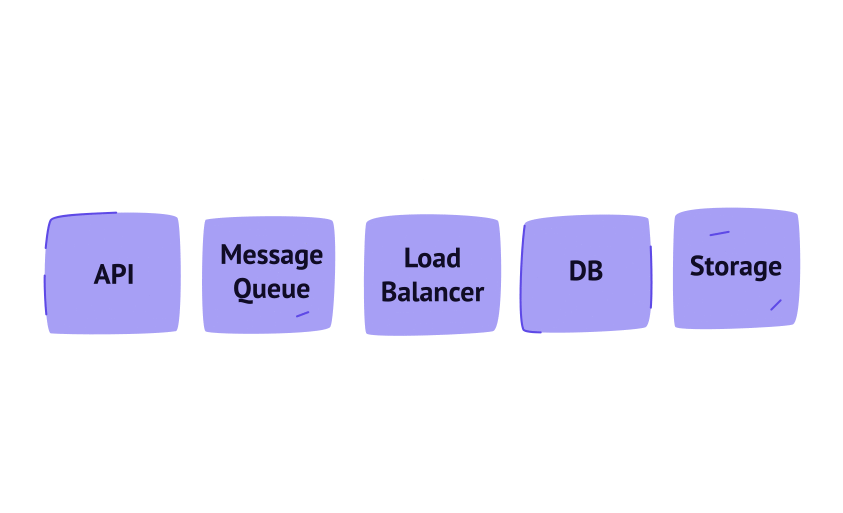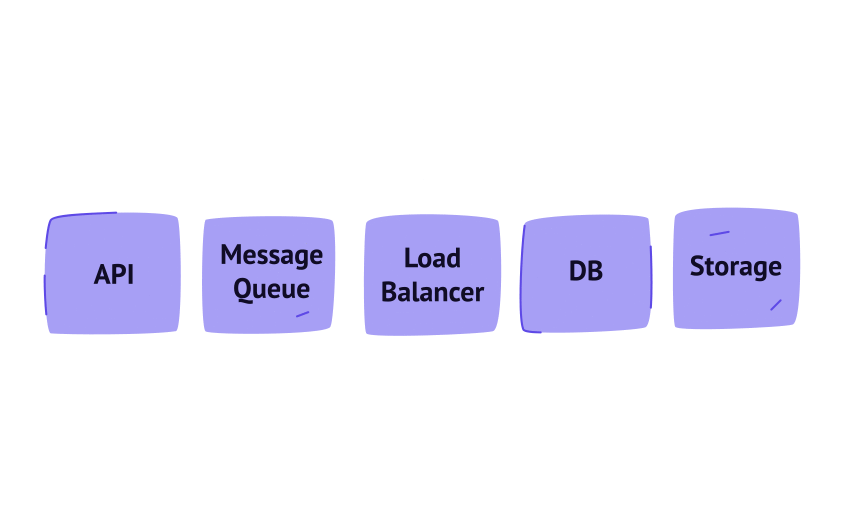
It has a dedicated server for different types of tasks:
- An API server for handling priority requests
- A cluster of database servers for storing dynamic data
- A Static Storage Server for storing BLOB data (images, audio, and other files)
- The Workers for managing complex tasks that are not required to be done in real-time
However, each server can still be a potential bottleneck. Let’s look at them one by one and see how we can avoid any possible scalability issues with each of them.
API server
As we’ve mentioned earlier, API servers handle requests related to the app’s main functionality. For example, if we’re talking about social media, it can be user authentication, loading the feed, displaying comments, etc.
As the number of app users grows, the number of API servers grows, respectively, so that the increased load can be distributed among them. If the application is used globally, clusters of API servers appear across the globe and the Load Balancer directs each user request to one of the servers within the closest cluster. As far as related requests can possibly be handled by different servers, it is crucial for API servers not to store any user data. Here’s why.
Let’s go back to the previous example with the profile image. Let’s say user requests are handled by four API servers. For example, server 1 receives a user request to update the image and saves it in its file system. As it did so, next time when the user makes a request to view the image and it is handled by server 2, 3, or 4, the image won’t display because it is stored on server 1.
Another reason not to store any data on API servers is that, at any moment, each of them can be terminated or suspended by the Load Balancer. That’s why there are servers meant specifically for storing images, called Static Storage Servers.
Before we proceed to Static Storage Server - if you have any questions at this point, you can always contact us for a free consultation
Your friends at yellowStatic Storage Server
A Static Storage Server is responsible for two tasks:
- Storing static data that doesn’t change over time, e.g. user media files
- Quickly grant access to the stored files to other users
While the first task does not cause any problems, the second one might during peak traffic.
Let’s say you’re a popular Instagram blogger with 1 million subscribers. When you take and post a new photo, each of your subscribers rushes to your account to be the first one to like it or leave a comment. One million users reaching one pic simultaneously is a significant load on the Static Storage Server.
To avoid downtime, there is a solution called the Content Delivery Network (CDN). These are a kind of caching servers that promptly deliver content to the users. Just like API servers, content delivery network servers can be located all around the world if the app is used globally. They store the files that are most popular among users and swiftly deliver them upon request. Let’s see how it works.
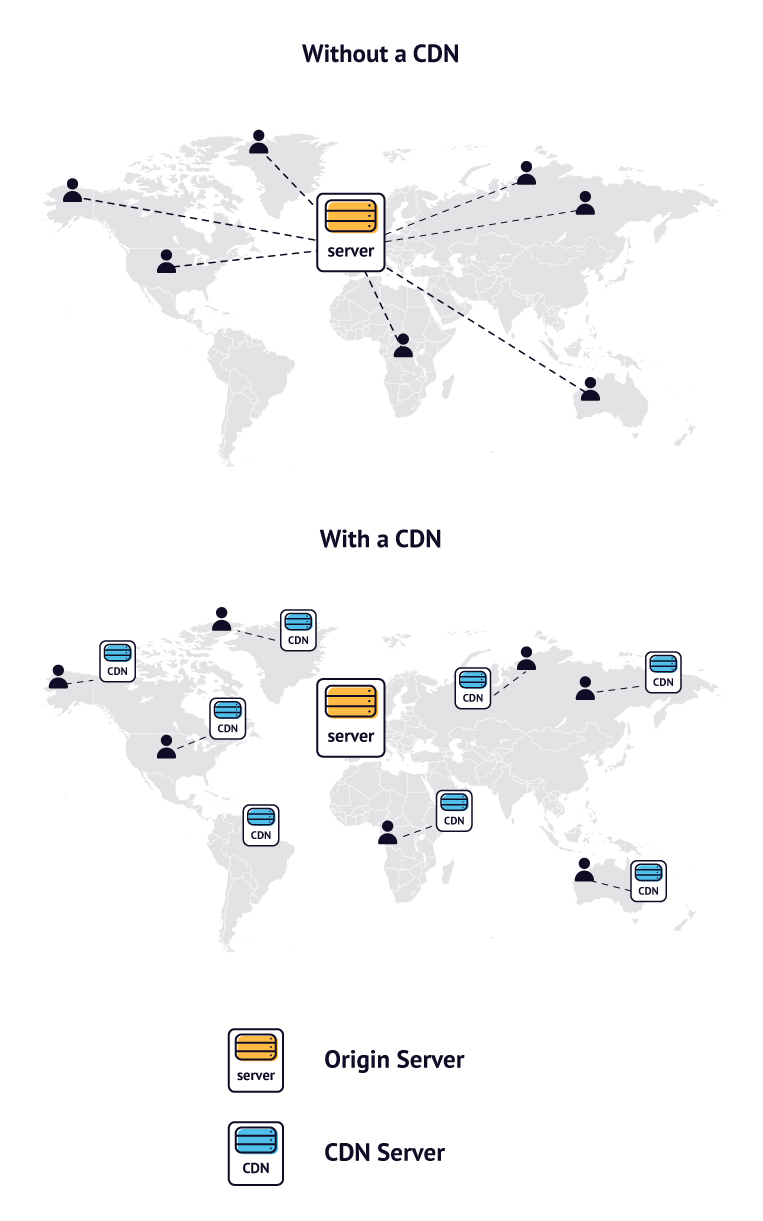
Let’s say you watched a funny cat video on YouTube that is stored on the Static Storage Server in California. You decided to share it with your colleagues and posted the link in a group chat, saying “Guys, check it out, it’s hilarious!” If all of your colleagues open the link simultaneously, it might cause a strain on the server. That’s where the CDN comes in.
When you open the video for the first time, it gets uploaded to the closest CDN server. So if you share the link with your friends, they will request it from the CDN, not directly from the Static Storage Server. Therefore, static storage servers are protected from overloading and users enjoy super-fast video loading because the server is close to them.
Workers
Not all user requests require an instant reply from the server. They might require more time to be completed but, at the same time, don’t require a real-time reaction. These tasks can be run on the background while the user is busy with something else.
Such tasks include, for example, uploading a video on YouTube. A user isn't going to sit and wait until the video is processed. They would rather be doing something else when a push message or email notifies them that the video is successfully published.
Therefore, it is not reasonable to run such “demanding” tasks on API servers because they are time and resource-consuming. These tasks are handled by Workers and Message Queue.
Workers are run on special servers that, just like API servers, can scale depending on the load intensity. Message Queue acts like a task manager between API servers and Workers. As far as a Worker can process only one task at a time, tasks first get to the Message Queue and when a Worker is not busy, it takes the task from the Queue and processes it. If the Worker fails for some reason, the tasks stay in the Queue until the Worker recovers or is handled by another Worker.
Required technologies and frameworks
The amount of possible tools for implementing a web app is quite large. The final choices will always depend on several factors like the expected load, the app’s main purpose, requirements, external integrations, and desired functionality. The best way to succeed is to contact a team of specialists who can lend a hand. Still, the possible technology stack for developing a scalable web app may include:
- Frontend: TypeScript, React
- Frameworks: Next.js, Nuxt.js
- Backend: Node.js, Nest.js
- Database: GraphQL, Lambda, PostgreSQL
- Storing code: GitHub
Conclusion
Designing scalable web applications requires an engineering approach. However, in the long run, their advantages outweigh the time and effort put into the process. Additionally, creating a scalable web app or online service today is easier with the help of such tools as Docker and Kubernetes.
First of all, scalable web architecture is cost-effective and resource-saving. It’s not reasonable to use 20 servers working at half capacity if you’re fine with five working at top capacity.
Second, building scalable web applications gives you freedom in selecting a technology stack. You can design your own servers from scratch or choose from the available solutions tooled for specific tasks. For example, you can use Amazon S3, Google Cloud Storage, or Microsoft Azure Storage to power your dedicated Static Storage Servers.
That was a brief guide on what we consider good practices in making a scalable web application architecture. If you are interested in the topic, let us know in the comments on our LinkedIn page we’ll share more useful insights in the coming articles.
In addition, if you want to discuss a product or startup idea or need a project estimation, please contact us and get a free consultation! With our extensive web development experience, we are ready to help you.
Got a project in mind?
Fill in this form or send us an e-mail
Subscribe to new posts.
Get weekly updates on the newest design stories, case studies and tips right in your mailbox.